How Kroo maintains sanity in distributed systems — Part 2

8 October 2020 | by Kroo Marketing Team
This blog post was accurate when we published it - visit kroo.com or your Kroo app for the most up to date information
This article is a continuation of Part 1 in the series.
In Part 1 of this article series, we laid out some groundwork by explaining what Richardson Maturity Model and Hypertext Application Language (HAL) are and presented some examples of where it might be beneficial to build your APIs as a mesh of services connected via Hypermedia links.
In this part, I will demonstrate code samples from an illustrative project which leverages some of these concepts, using Clojure’s popular HTTP libraries, as well as some of Kroo’s open-source libraries
How to: Hypermedia-Driven RESTful Web Services in Clojure
The sample project uses an imaginary order fulfilment service as the domain.
Exposing HAL resources using Bidi and Clojure Liberator
Hypermedia Application Language resources are an excellent extension to RESTful interfaces when working with microservices.

To start with, we define our service endpoints using
bidi, a bi-directional routing library that allows us to not only define
endpoints and de-couple them from the HTTP verbs, but also easily generate
embeddable absolute URLs out of these endpoints.
The next step is to define a mapping between our endpoints and Liberator resource handlers:

and finally, using bidi/make-handler create a Ring handler and
hand it over to a Jetty server:

Each of the resource handler functions returns aliberator
resource. Liberator resources are in essence controllers, which through its
Actions, Decisions, and Handlers helps us define an RFC compliant HTTP handler
in a declarative way. It takes care of ‘merging’ the decisions, sending the
appropriate HTTP status codes, short-circuiting when we tell it that a
resource does not exist or a user is not authorised to name a few.
Clients consuming HAL discovery resource
Now, moving onto Hypermedia Application Language (HAL).
In order for the resources to be traversable, one has to introduce an entry
point where you can begin a conversation with the API. We can do that by
defining the aforementioned Liberator resource for the
:discovery handler, which maps to the root “/” endpoint.

In the example above, we are implementing Liberator’s:
:handle-ok, which will respond to GET requests with a HAL object.
We are using Clojure’s thread -> macro to assemble a Halboy
object, using the open-source
halboy
library. There are equivalents of this library for Java
Spring
and other languages and platforms.

The response contains absolute URLs to all the other endpoints this service
exposes, as well as a self link. Given the bidi routes and a
request object, Kroo’s open-source
hype
library can generate the right URLs — e.g.(hype/absolute-url-for request routes :orders)
.
The discovery resource can be ingested by
halboy, but is equally useful for manual traversal and exploration, as it is for
HTTP client libraries. What is apparent from the discovery output, is that we
have means of accessing sub-resources leveraging the templated
{articleId} .
A client library that supports HAL can automatically ingest the discovery resource and leverage templating capabilities to pre-configure all of the routes for a specific sub-resource. You can also configure your Postman collection to perform template substitution for you.
A more complex Liberator example
In the example below, we define a Liberator resource handler for the
:order handler, which in turn maps to the
/orders/:order-id bidi route.

As you can see in the example above, Liberator provides a consistent way to
perform checks for things like ‘exists’ and can explicitly return a 404 when
our function returns a falsy value. You just need to declare the Decision and
a corresponding Action, e.g. :exists? and
:handle-not-found Liberator takes care of making it into an RFC
compliant HTTP service.
Clients interacting with services
So how do you communicate between HAL enabled endpoints?
Using
halboy, it’s quite simple. You can use the library built-in HTTP client to
initiate the conversation with another service, using its discovery endpoint
as the starting point.
From then on, the library is aware of all the linked resources, e.g.
:items as well as all of the path parameters that the resource
accepts (e.g. :item-id).
Bonus: Distributed Tracing with OpenTracing, Halboy, and Jaeger
Now, in order to fully unlock the observability and traceability of your HAL RESTful Web Services, you can extend your service with distributed tracing or what is often referred to as APM (Application Performance Monitoring).
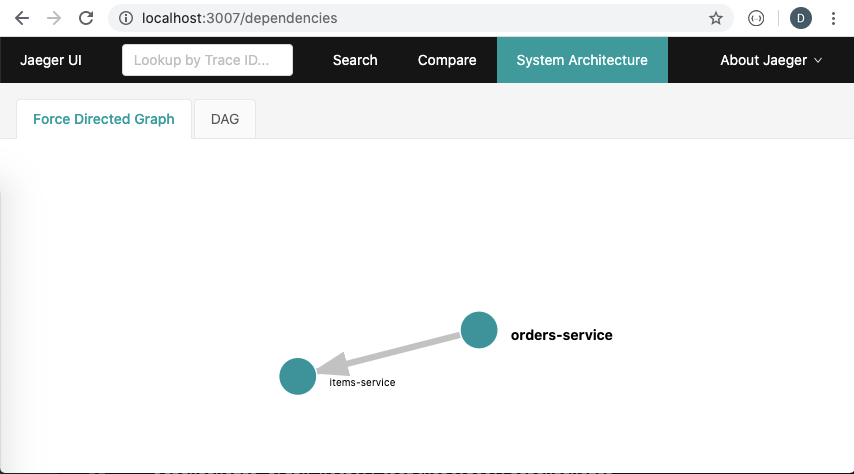
Distributed tracing will further extend the discoverability of our Hypermedia enabled web services. It will do that by automatically collecting traces across services and forming ‘spans’. It will automatically generate Directed Acyclic Graphs (DAGs) of the network of services, giving us a holistic view of all of our micro-services top down.
Through sampling of individual requests across services, it will give us detailed traces and allow us to visualize bottlenecks or issues in our services, all the way down to a database query, as illustrated in the screenshots below.


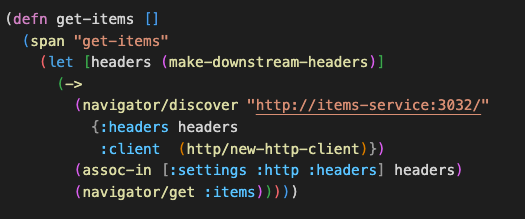
Enabling OpenTracing in a Clojure microservice is as simple as adding a few
hooks at the root of your application to start the trace sample collection and
sending it to a frontend like Jaeger, as well as adding a middleware wrapper
wrap-tracing that will automatically annotate requests and
tracepoints with information received from the headers in order to form a span
across services and DB calls.

In this example, we are using
openconsensus-clojure to automate the collection of traces and sending it to our log files,
as well as to the Jaeger UI.
Conclusion
In this follow up article to the Part 1, we demonstrated some code samples from an illustrative project and provided a sneak peek into how we build discoverable, robust, and traceable APIs at Kroo, leveraging Clojure and its great library eco-system.
The example project closely resembles how Kroo builds its domain services and
illustrates some of the Kroo’s open-source libraries:
halboy,
hype,
liberator-mixin
which you are welcome to use and contribute to!
P.S. We’re hiring 🔥🚀. If you’re interested in joining Kroo, please see our careers page: https://kroo.com/careers/.




